


TITAA #62: December AI Madness
Gemini 2 & Veo - Narrative - ModernBERT - Moodboards - 3D W's - Alife


Well, there was a lot of new stuff the past 2 weeks, and I’m anxious to send this and finish a game with a glass of bubbly. So (sadly) no intro, just onto the long news. I’m sending a December books/tv/games recs post to the supporters tomorrow! Happy New Year!
TOC (links on the web site):
AI Creativity (Video, Image-Related, 3D, Misc)
NLP & Data Science — lots of Gemini stuff, ModernBERT etc.
AI Creativity
Video
Veo 2 (only text to video), in limited beta access from Google, looks really good from the samples. Checkout “The Heist,” a mini AI feature made with it using only text prompts.
Check Heather Cooper’s recent (posted on X) comparisons of some big models using image2video, same prompts — I tried this one of hers in Veo.

I have Veo early access and so I tried her prompts without the init images. The motorcycle one was very close to hers, but the lighting is interestingly different — I think it honored the “noon” lighting better.
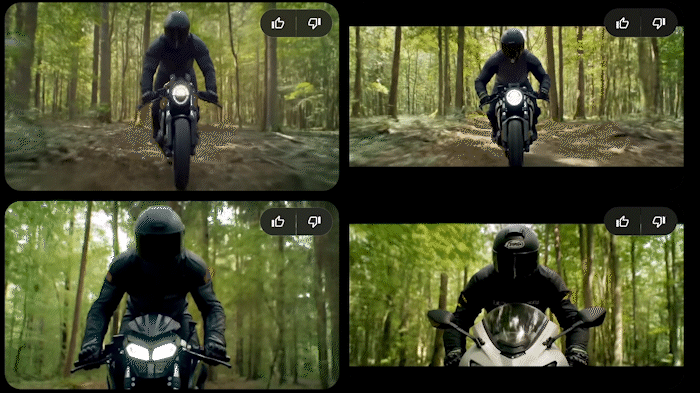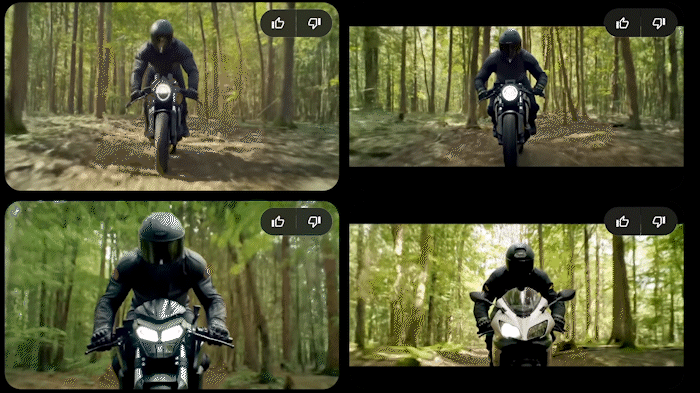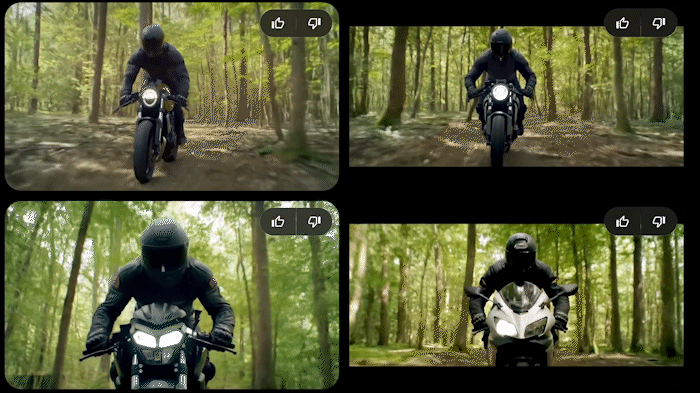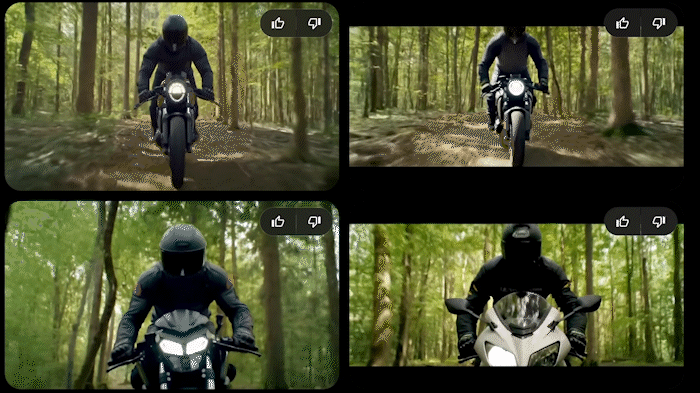
The drone footage one is really good in Veo, but doesn’t show the drone except for a tiny bit in one; I think this is a difference due to not having an init image. Linking this as video on the webpage (downsampled, resized) instead of a gif, sorry:
DynamicScaler. Creates panoramic video for VR/AR uses, including from input images.
LinGen — minute long video generation (research).
For folks wanting API access to existing released models, here’s a useful post by fofr on how to use the many current video models on Replicate and how they might differ. Those of us after speed are really into the LTX ones.
Image Gen Tools
Midjourney’s Moodboards turn out to be a lot of fun, although a bit tricky to use. I populated 2 boards with CC0 works and dead artists, for an architectural/sketchy version and a surrealism look. I then did the same prompt with each one, to see the difference: “a building.” I think the floating building might be because I included an Escher in the architectural version?

Tips: Turn off any weirdness or other settings, they override and break the moodboard style one. You can combine a tuned (by ratings) style with moodboards though, and it opens up more interesting possibilities.
Google Labs Whisk image generation experiment (US only) is fun, and shows the strength (and limits) of using image to text to prompt to image as a workflow. The UI asks you to combine a character, a scene, and a style image, and then Gemini multimodal models interpret and caption the images (you can read this and tweak if you want), and then construct a combo, using any additional prompt advice you want to give. I’ve been doing some experiments with emoji and artworks, and had interesting results. The top one featured no prompt fixing at all, just a Boschy style attempt and a Conway Castle Turner painting:

You can see that the style isn’t truly Bosch. I had an even harder time with the Klee style below, even with some attempted prompt fixing (bottom row has some blocky stuff in the one on the left, but ignored other directions).
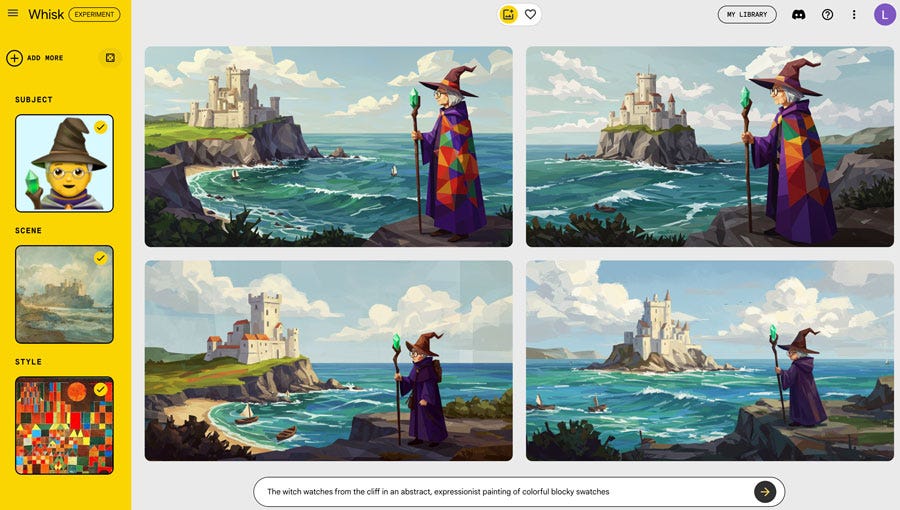
It’s still fun!
You can also play with the new workflow tool in tldraw computer, now available. It does a similar thing, using input images for caption creation and then generation. See the Narrative section for its story gen template.
3D
Niantic’s Scaniverse app for mobile lets you scan a scene and then processes the splat right on your device (quite fast on my new iPhone 16) and then upload to their map/cloud. I really enjoyed visiting their map in VR on my Quest, via the browser app. It’s fun seeing what people have been scanning, and getting little fragmentary bits of the rest of the context — it’s like looking at someone’s attention. Plus kind of melancholy creepy music. I tossed up a splat from inside old Lyon (I was standing on the ground, so you can see how it feels like flying to navigate in these things):

PanoDreamer: 3D Panorama Synthesis from a Single Image (h/t DreamingTulpa): “we present PanoDreamer, a novel method for producing a coherent 360° 3D scene from a single input image.” Code coming.
Geez, this is shockingly good with hard images: FreeSplatter: Pose-free Gaussian Splatting for Sparse-view 3D Reconstruction. [Github]. Demo output just of the multiple views (it made a splat too, and would do a mesh on demand).

Interactive Scene Authoring with Specialized Generative Primitives — this is clever, it looks like it goes thru a voxel phase (3d pixels) to then generate and splat.

I’m starting to confuse all the “W” releases in this space, tbh:
Wonderland: Navigating 3D Scenes from a Single Image, from Snap. This is splat based, and seems quite similar to FreeSplatter above.
Justine Moore (on X) showed a peek of WorldLabs (Fei-Fei Li’s coming soon 3D world lab, mentioned last issue in the world generation section!).
Dylan Ebert’s funny, short, and good summary of the 2024 3D AI stuff (X), from splats to suddenly great meshes all over the place. tldr not on X: we can now generate good meshes with AI.
Misc AI
Pattern Analogies: Learning to Perform Programmatic Image Edits by Analogy (h/t DreamingTulpa). Adobe and others.

⭐️ Automating the Search for Artificial Life with Foundation Models - From Sakana AI, David Ha/hardmaru’s startup in Japan. This is wonderful and meaty, with amazing images. Into boids, Lenia, and other alife agent evolution? Umaps, latent spaces?

Book Search by Claude: Sharif Shameem who did the great Lexica search api way back in the old days (with semantic search) made a toy search interface for books by description, using Claude. It’s pretty good! When it fails to match precisely, it gives you similar ones that might work for you.
Map search by AI (godview)— similar, I guess, but honestly I found some things I couldn’t easily find otherwise. It doesn’t link to any source, but I could verify some of them in various web searches?
Audio: Introducing OCTAVE (Omni-Capable Text and Voice Engine) • Hume AI: “A frontier speech-language model with new emergent capabilities, like on-the-fly voice and personality creation.” and also MMAudio, for good soundfx on your video.
Procgen / Misc / Web
Badquarto’s Taper #4 for fall 2024. Small textual poetics on the theme of superstition.
City Roads — render roads from a city as a downloadable file (png or svg).
Tutorial: Creating Dynamic Terrain Deformation with React Three Fiber on Codrops
And tutorial: 3D Typing Effects with Three.js on Codrops
Games
⭐️ The Dagstuhl report from 2024 on games: Computational Creativity for Game Development (Dagstuhl Seminar 24261). The actual PDF is a tiny link on the left side. There were a lot of working groups looking at AI and games, and where the limits were. The pdf is 84 pages and it’s a deep read. (😄: “In this working group, we asked the question – “Do bots always have to be efficient?”)
One bit from a group looking at AI for romantic comedies:
Rather than trying to guide the narrative precisely, an AI system could instead simply help sculpt the space of opportunities. However, assessing what outcomes are “funny” or “romantic” remains a challenging, subjective and potentially unsolvable (in the traditional sense) problem.
Another workgroup, on “Meaningful Computational Narrative,” has a good section covering story and narrative at several levels. “Terminology sometimes used by game developers is as follows: The nebula is the cloud that contains all possible stories. The fabula consists of locations, characters, events, and chronology which define the game world. The fabula restricts the storylines to a subsection of the nebula.” Then they cover plotlets, which seem to be related to storylets if not the same:
A plotlet can be considered a story “beat”. It consists of the following elements:
Pre-conditions, which specify in which circumstances the plotlet can take place
Action, which specifies which generally formulated action can lead to the plotlet
Description, which in general terms describes the situation that the player is in
Selectable actions, which are generally formulated actions that a player can take when the plotlet runs
Post-facts per selectable action, which define the new situation
They suggest an AI helper can help find and fit a plotlet to a situation, customize options, and summarize results.
Game Developer's 2024 Wrap-Up: 10 must-read Deep Dives. Includes “Player Centered Narrative Design in Slay the Princess.”
The Case Against Gameplay Loops (via v and others). “But if the action isn’t born out of meaning…how did it get there in the first place?”
2024 top 10 web games: “2024 is nearing its end, and as is tradition here at bontegames, it's time to share my personal favorites among all the new games I featured…”
Narrative
Tools/Apps
The tldraw.computer app is out and playable — it uses Gemini models behind the scenes. I have fiddled with their demo apps, and had fun… but it needs some more time to sink in. There is me trying their story generator, which works by asking you for input— character, problem, etc, then makes an outline of 3 chapters, then fills in each chapter. (It didn’t really obey the plot instruction exactly, tbh):

(It reminds me of Patchwork, though that might just be the canvas and links.) This is a helpful video for Patchwork, the new Midjourney storyboard-world-gen experiment of a few weeks ago. For instance, how to get your style refs and other settings to be used, which wasn’t obvious to me (it’s a bit manual). (Otoh world management, as in how to navigate and even do it, is opaque and/or buggy for me, so I might wait a little while.)
Ed Catmull (Pixar) joined Odyssey to work on 3D worlds.
Audio: Introducing OCTAVE (Omni-Capable Text and Voice Engine) • Hume AI: “A frontier speech-language model with new emergent capabilities, like on-the-fly voice and personality creation.”
Research
CharacterBox: Evaluating the Role-Playing Capabilities of LLMs in Text-Based Virtual Worlds. “CharacterBox consists of two main components: the character agent and the narrator agent. The character agent, grounded in psychological and behavioral science, exhibits human-like behaviors, while the narrator agent coordinates interactions between character agents and environmental changes.” They also fine tuned smaller models! Code available.

The Emotion Dynamics of Literary Novels. “Our findings show that the narration and the dialogue largely express disparate emotions through the course of a novel, and that the commonalities or differences in the emotional arcs of stories are more accurately captured by those associated with
individual characters.”
Creating Suspenseful Stories: Iterative Planning with Large Language Models. In case I missed it earlier in the year, a Riedl joint that came up in a thread yesterday on Bluesky. They set up suspenseful story progression using prompts to enforce failure for the protagonist’s goals, among other tricks. Good prompts. They found their method improved enjoyment of GPT generated stories (and their internal logic), and that clues to protagonist failure enhanced enjoyment.
Generating Long-form Story Using Dynamic Hierarchical Outlining with Memory-Enhancement. Another hierarchical generator, but this time with knowledge graph memory for coherence. “A Memory-Enhancement Module (MEM) based on temporal knowledge graphs is introduced to store and access the generated content, reducing contextual conflicts and improving story coherence. Finally, we propose a Temporal Conflict Analyzer leveraging temporal knowledge graphs to automatically evaluate the contextual consistency of long-form story.” AI always comes back to a database.
“We use LLM to extract triples for every sentence and then add the current chapter number to form quadruples. To access the relevant content, we first conduct entity based quadruple retrieval on TKG and then apply LLM to filter the retrieved” set. I think it’s non-trivial to do the knowledge extraction from the text, personally. Not to mention the difficulty of getting temporal event ordering correct (see mid-month post).
Modeling Story Expectations to Understand Engagement: A Generative Framework Using LLMs. Study on Wattpad fiction, checking audience engagement (reading, liking) vs. literary features. Interesting! “Our method generates multiple potential continuations for each story and extracts features related to expectations, uncertainty, and surprise using established content analysis techniques.”
MLD-EA: Check and Complete Narrative Coherence by Introducing Emotions and Actions. Hmm, are we starting to get work on smaller, focused models in narrative, which is what I’d like to be seeing? “MLD-EA extracts the actions and emotions of the characters in the input story and guides LLMs to find logical loopholes in the narrative by following the rules of interaction between actions and emotions.” There is a LoRa tuned 8B model, compared to comparable baseline models. Unfortunately the stories are short toys; but there is nice detail on training in the appendix (though no model weights?).
NLP & Data Vis & Data Science
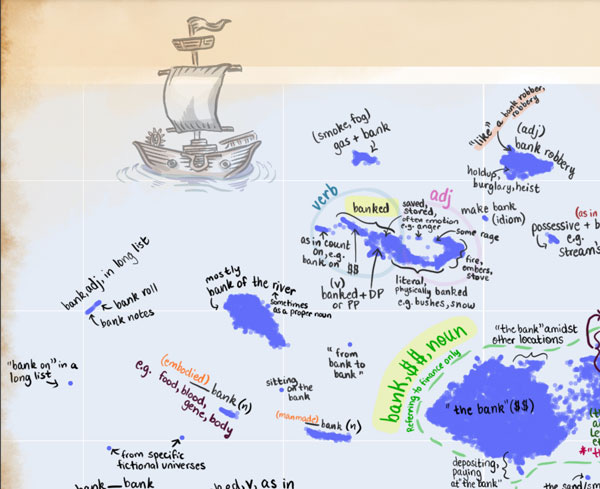
Tokens, the oft-overlooked appetizer: Large language models, the distributional hypothesis, and meaning. This paper has some amazing figures and charts in it (and ngl, one looks like the work of a mad detective in a garret chasing a serial killer LLM). It’s also meaty for linguistic reasons.
“As tokens are the bridge from raw text to numbers that LLMs can work with, from our world (koinos kosmos) to the LLM’s internal world (idios kosmos), they play a crucial role in the architecture of LLMs, yet their impact on the model’s cognition is often overlooked.” They give an example of hallucination of the meaning of the fake work “besperpled” that may be influenced by tokenization.
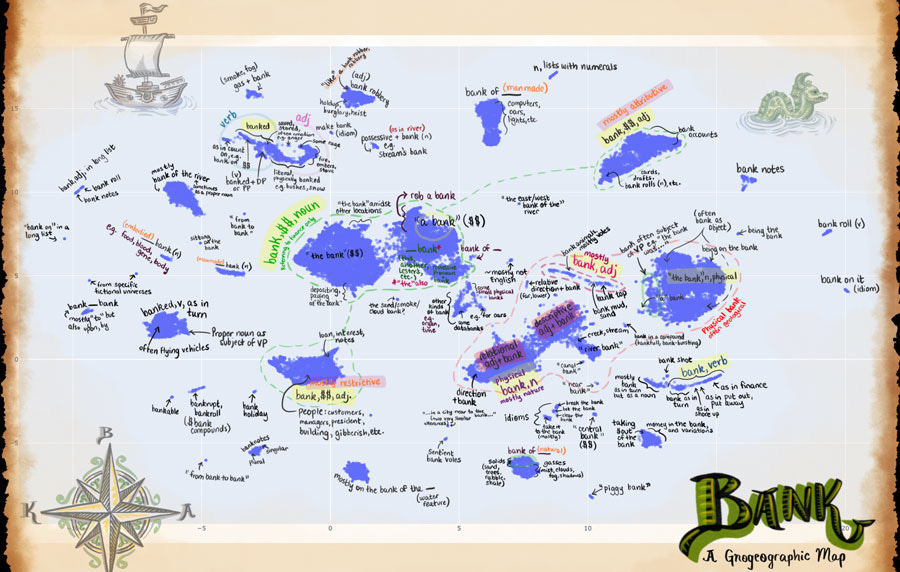
Detail of part of that:
Nomic’s GPT4All local client release: Scaling Inference Time Compute with On-Device Language Models in GPT4All. “This Reasoning release improves local AI capabilities, empowering users with advanced features such as Code Interpreter, Tool Calling, and Code Sandboxing — all running securely on your own hardware.
Goodfire’s Mapping the Latent Space of Llama 3.3 70B with SAE (sparse auto-encoders), providing an API. “You can browse an interactive map of features that you can then use in the API, and we also demo the steering effects of some of our favorite features.” Their writeup includes stylistic steering of a fact into pirate speech, and notes that at a certain threshold, the style is strong but the factuality is impacted.
“The model then shifts style fully but factuality slowly begins to degrade. For instance, at strength 0.6 most facts are correct, apart from the galaxy’s size, whereas at strength 1 many facts are incorrect (and are rescaled to nautical units such as knots and far more mundane magnitudes). The mechanism by which factual recall is damaged by latent steering is unknown, but would be very interesting to understand.”
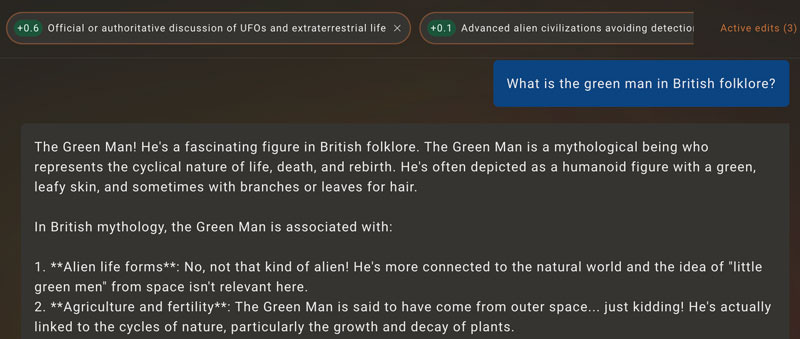
With their API playground, you can see how Llama reacts in ordinary conversation if you steer by a feature. For instance, asking it to tell me about the green man figure in folklore, with a steering towards “belief in UFOs”, it brought up aliens a lot, but then said it was joking, because they aren’t relevant. Very interesting behavior.
⭐️ ModernBERT: “Finally, a replacement for BERT.” Amen. NLP needs BERTs. And how to Fine-tune classifier with ModernBERT in 2025 - useful tutorial from Phil Schmid for use with the excellent new ModernBERT from fastai.
Building effective agents, from Anthropic. Goes over different workflows with programming agents. Useful.
GitHub - guestrin-lab/lotus: LOTUS: A semantic query engine - process data with LLMs as easily as writing pandas code. (A project from Stanford I may have mentioned previously; I keep eyeing it without having tried it, sorry to say.)
"Wave Pulse" - a pretty amazing project doing real-time radio content analysis (audio, classification, etc). Lots of tech detail.
Building with new Gemini tools:
Gemini Coder - a Hugging Face Space by osanseviero (with github code).
cookbook/gemini-2/search_tool.ipynb — there are a LOT of new cookbook code samples for Gemini; this is one that shows use of search with Gemini in a jupyter notebook via API. I’m wondering if it can be a reliable scraper now.
Web app starter kits: I’m also impressed by Alex Chen’s group’s react starter kits for web app building, some in this repo, and this multimodal live api example (“This repository contains a react-based starter app for using the Multimodal Live API over a websocket. It provides modules for streaming audio playback, recording user media such as from a microphone, webcam or screen capture as well as a unified log view to aid in development of your application.”)
Recs
I’m putting out a special recs detailed post tomorrow for December’s recs, because I’ve read some top notch stuff, watched some great stuff, and played some great games this past week. Most of them were briefly mentioned in the Best of 2024 Media Recs post for subscribers. Consider upgrading!
A Poem: Fairbanks Under the Solstice
Slowly, without sun, the day sinks toward the close of December. It is minus sixty degrees. Over the sleeping houses a dense fog rises—smoke from banked fires, and the snowy breath of an abyss through which the cold town is perceptibly falling. As if Death were a voice made visible, with the power of illumination … Now, in the white shadow of those streets, ghostly newsboys make their rounds, delivering to the homes of those who have died of the frost word of the resurrection of Silence.
Happy New Year! Er, maybe that poem was a bit dark. Turn up your gas fire and radiator. Recs post tomorrow to celebrate :)
Best, Lynn (@arnicas on mostly bluesky, ex twitter, mastodon).
very cool