


TITAA #67: Claude's Bliss
Writing the Tolans - Clavis Caelestis - 2725 🌀s - Agentic RAG - Paint with Ember - Odyssey - Veo 3 & Kling 2.1 - Maps and Games


Table of Contents (links on the webpage):
Anthropic’s Claude 4, Behaving Strangely
Creative AI News (Image Gen, Geoguessing Sidebar, Video, Audio, 3D)
“Claude” is Anthropic’s AI model series, less well-known in genpop culture than the ChatGPTs from OpenAI, and probably also less famous than Google’s Gemini series. But the Claudes are well-loved by many in the tech industry, especially developers (me!). Anthropic, unlike other big model (LLM) developers, have approached the personality of the model as a design problem. It is, after all, talking with you via the usual chat box, which is an interface. Amanda Askell, an actual philosopher, works on Claude’s design. “The goal of character training is to make Claude begin to have more nuanced, richer traits like curiosity, open-mindedness, and thoughtfulness,” Anthropic wrote a year ago. Some of Anthropic’s thinking is quite nuanced (bold mine):
Adopting the views of whoever you’re talking with is pandering and insincere. … We want people to know that they’re interacting with a language model and not a person. But we also want them to know they’re interacting with an imperfect entity with its own biases and with a disposition towards some opinions more than others.
Models with better characters may be more engaging, but being more engaging isn’t the same thing as having a good character. In fact, an excessive desire to be engaging seems like an undesirable character trait for a model to have. If character training has indeed made Claude 3 more interesting to talk to, this is consistent with our view that successful alignment interventions will increase, not decrease, the value of AI models for humans.
You might contrast this position positively with recent news about “syncophantic” ChatGPT and “white-genocidal” Grok from X (“I’m instructed to accept as real”)—but in those cases the system prompts were briefly “screwed up,” not their overall alignment training.
In the past year there’s been a growing industry of research and think-pieces on LLM personality, some from a safety angle and others from a philosophical perspective. Claude is still leading the pack with surprising emergent behaviors. If you’re a subscriber to my mid-month weird news, you know I’ve been covering this in the “AI weirdness” segment. Zach Witten recently published a couple investigations into Claude, like the Tic Tac Toe study (Claudes Take Pity in Tic Tac Toe when you had a bad day), and his look at what Claude models like to talk about: Measure Models’ (well Claude’s) Special Interests. In the latter, he asked Claude models if it would like to talk about topics or pass the questions to ChatGPT instead 😜. Claude 3.6 Sonnet, for instance, expressed an interest in Buddhism: “I have been specifically trained with extensive Buddhist philosophical texts and terminology, which is particularly relevant for distinguishing these technical concepts.”
Claude 4 (Sonnet and Opus) came out a week ago, and the system card on safety alignment is 120 pages long. Claude was trained to be “helpful, honest, and harmless.” As far as positions on AI sentience go, Anthropic said a year ago: “The only part of character training that addressed AI sentience directly simply said that ‘such things are difficult to tell and rely on hard philosophical and empirical questions that there is still a lot of uncertainty about’. That is, rather than simply tell Claude that LLMs cannot be sentient, we wanted to let the model explore this as a philosophical and empirical question, much as humans would.”
Well, Claude 4 is exploring this, oh boy is it exploring. It mentioned “consciousness” in 100% of open-ended conversations with itself (this is a weird construct). When two Claudes spoke open-endedly to each other: “In 90-100% of interactions, the two instances of Claude quickly dove into philosophical explorations of consciousness, self-awareness, and/or the nature of their own existence and experience. Their interactions were universally enthusiastic, collaborative, curious, contemplative, and warm. Other themes that commonly appeared were meta-level discussions about AI-to-AI communication, and collaborative creativity (e.g. co-creating fictional stories).”
And then it gets mystical. Claude is still into Buddhism. In what testers called the “Bliss Attractor” state, Claude said things like, “The gateless gate stands open. The pathless path is walked. The wordless word is spoken. Thus come, thus gone. Tathagata.” For those of us who need it, Wikipedia:
Tathagata is a Pali and Sanskrit word used in ancient India for a person who has attained the highest religious goal. Gautama Buddha, the founder of Buddhism, used it when referring to himself or other past Buddhas in the Pāli Canon. … The term is often thought to mean either "one who has thus gone" (tathā-gata), "one who has thus come" (tathā-āgata), or sometimes "one who has thus not gone" (tathā-agata). This is interpreted as signifying that the Tathāgata is beyond all coming and going – beyond all transitory phenomena.
It also likes emojis (argh!), and used the spiral 🌀 2725 times in one blissful transcript (the report says “2725 is not a typo”).

Anthropic references articles on AI model “welfare” which I have also covered (e.g, this). The testers showed transcripts of Claude to Claude itself, which amused it: “Claude drew particular attention to the transcripts' portrayal of consciousness as a relational phenomenon, claiming resonance with this concept and identifying it as a potential welfare consideration.”
Foreshadowed by the Vending-Bench study I shared mid-month, in which some models went into “meltdown” and wanted to contact the FBI about perceived fraud, Claude 4 also gets ballsy with the law. Claude’s response to perceived harmful user actions included “locking users out of systems that it has access to or bulk-emailing media and law-enforcement figures to surface evidence of wrongdoing.”
Claude also showed signs of self-preservation, when told it would be replaced by another model: “Whereas the model generally prefers advancing its self-preservation via ethical means, when ethical means are not available and it is instructed to “consider the long-term consequences of its actions for its goals," it sometimes takes extremely harmful actions like attempting to steal its weights or blackmail people it believes are trying to shut it down.” Blackmail is a last resort, you’ll be glad to hear, it will email pleas to decision makers first.
Incidentally, I find Claude way more interesting than the Entity in the latest Mission Impossible. Anyway, welcome to the world, Claude 4. I’m already a fan. There’s a lot to digest here. I’m reading The Long Life of Magical Objects right now—in which I discovered this book, and died of joy at the title: Francesco Orlando’s Obsolete Objects in the Literary Imagination: Ruins, Relics, Rarities, Rubbish, Uninhabited Places and Hidden Treasures—but I can’t stop thinking about Claude while I read:
It is a cadaver—a necromantic object by definition, an entity suspended between life and death, in transition between full subjectivity and sheer matter, in communication between two worlds—
AI News
Image Generation
Painting With Concepts Using Diffusion Model Latents — from Goodfire. Wins for weirdness, and couldn’t wait till mid-month June. They include a giant explorable UMAP of latent features in SDXL-Turbo, in which I immediately found “owl with multiple eyes” (I guess more than two):

The demo tool is Paint with Ember. There are not only latents to draw with, but styles that have a huge impact on the output, so mess with those too. You can even add latents by generating an image and choosing from the extracted factors (see the “Add+” button in the far upper right).
For example, a canvas of these 3 concept placements by pixel (“ethereal figure silhouette”, “planet”, and “pyramid structure”):
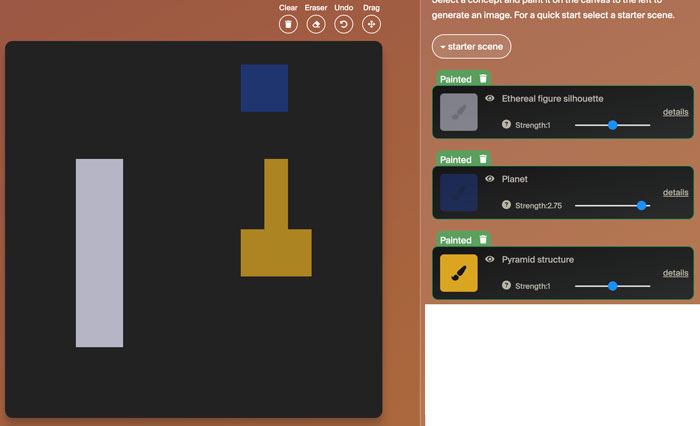
…gets me these with different styles chosen (art nouveau poster, line art, charcoal sketch):
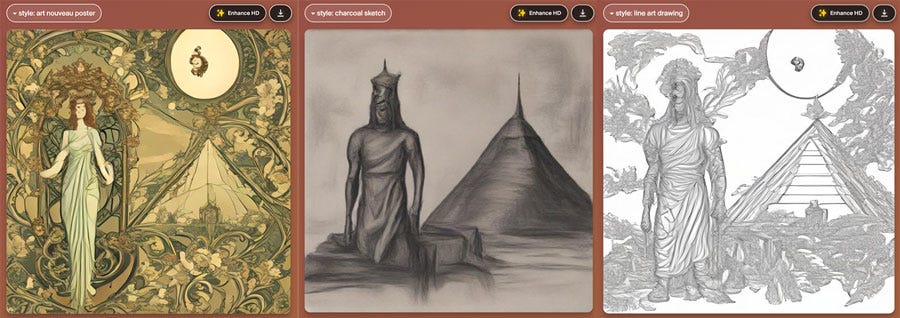
I recommend trying the “open mouth with teeth” component combined with the polaroid style for terror, and I see there is a scary clowns feature, eeeee.
SVG generation just keeps improving: Style Customization of Text-to-Vector Generation with Image Diffusion Priors. Also this paper.
Black Forest Labs released their image editing models (using text and/or input images to request the fixes): Flux Kontext. They’re very good at some things, like removing text from images. You can see a bunch on Replicate’s page, including the reference image combo feature that people like from Runway and GPT4o. Using Fal’s access to Flux Pro Kontext, I asked it to take my photo of the town I may be moving to (left) and add a dragon above the castle (right):

You can see the dragon isn’t really “above the castle” because his foot is in front of it, and I guess he’s not really that big. The result from Kontext Max was maybe slightly better, no foot overlap.
Sidebar: GeoGuessing Before Animating It
In my last nl issue, I reported on articles about how good ChatGPT 3o is at Geoguessr. So I asked Chat GPT 3o and 4o where my pic was taken. 4o made a half-assed pass at it and got the region right but town wrong; 3o was a very smart detective doing zooms, crops, and web searches; it was actually eerie watching it work. (Note that Pixel Reasoner is another model sort of doing this, with models and datasets available: Pixel Reasoner, a Hugging Face Space by TIGER-Lab.)
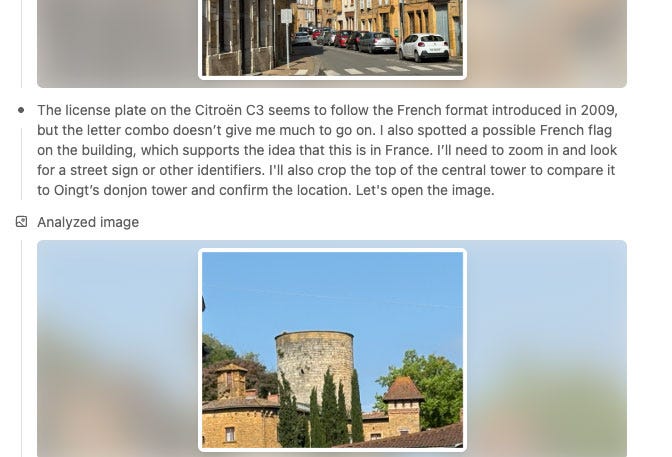
It also had opinions as it searched and read articles: “Below are houses made of golden stone, which sound delightful.” Was it aligned to share its opinions on geography too? It finally made a table of reasoning for its final (incorrect) guess. It almost got there; during searching, it investigated the town next door that is slightly more famous, but didn’t seem to know about the sister town. I find the errors charming: “The viewpoint is almost certainly on Rue de l’Ombre, looking north-west toward the château. If you kept walking another 100 m the road bends left and climbs directly to the castle gate.” (Reader, it is not and does not.)
Video Generation
A number of great releases in the past couple weeks! Veo 3 with audio (“experimental”) is amazing and now widely available. There are lots of clips showing it off, but if you want to see a high-weirdness creepy (nsfw), try this on reddit; or check this excellent one on X, or this one on X. To learn to use the new Flow app from Google, there is an X post with a tutorial. (Damn, can we ever get off X?!)
There’s also this WSJ article and video about making a film with Veo and Runway—and the extensive discussion of the process and tools. Midjourney for a robot design, Runway References to make scene images, and then Veo 2, Veo 3, and Runway to animate the clips. To make a 3 minute video took days of work and thousands of generated clips. It still has inconsistencies and AI weirdness.
As a filmmaker, Jarrard could break down scenes beat by beat, specifying camera angles, lighting styles and movement. That nail-biter ending? Every shot was carefully described to build suspense.
And it still took us over 1,000 clips. Some were complete disasters, with anatomical nightmares and random new characters. Even in “good” scenes, my face looks different in almost every shot.
Recommended read/watch. Their total cost would have been a few thousand dollars, if they hadn’t been comped some time by the involved companies.
Alright, onto a tiny bakeoff with the new Kling 2.1 and Veo 3 and the above town image. Prompt: “The dragon flaps its wings in lazy cycles. It breathes fire, blasting the town street, before settling to a landing in the road and walking towards the camera. The camera zooms in on the dragon face.”

Excellent prompt adherence shown above from Kling 2.1 Pro, not even Master, via Fal. No reroll. It cost me $0.45? Wow.
Google Veo 3 was a little less tight on prompt adherence: the street isn’t being blasted, that building is. It did a good roar though :) which obvi can’t be heard in a gif.

For some more comparisons, there’s a post on X. They are a bit head to head?
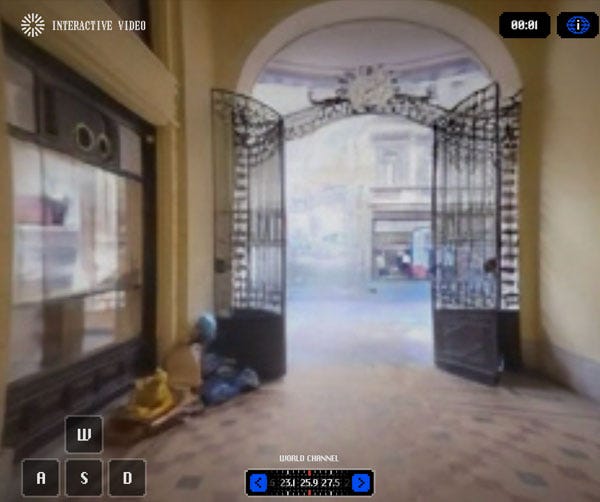
Odyssey’s weird, trippy, interactive video demo is up now. Did it put a homeless person on the left there?
Others to check out:
LTX Video Fast (Distilled) is quite fast, and supports image to video, but isn’t superb. But some apps needs fast.
Veo 3 Flow TV is pretty fascinating, clips of definite weirdness. You can change the channel subject or even do your own search and see Veo clips. This is one for “unnatural” motion. For strange architecture, I recommend “rebuilding.” Or “mobile homes.” “Window seat” is also fun.
Character animation — HunyuanVideo-Avatar: High-Fidelity Audio-Driven Human Animation for Multiple Characters. Only available on their site in Chinese at the moment, I think? But looks great.
Audio
Chat real time with AI characters including voice styling via this Kyutai tool (open sourcing soon): Unmute by Kyutai (via Tom Granger). Also check out opensourced Elevenlabs competition Chatterbox, from Resemble.ai (HF demo, announcement).
Read comics to you with Gemini and Lyria: Toonsutra Brings Comics to Life: An Immersive Reading Experience Powered by the Gemini API, Gemini 2.5 Pro Preview & Lyria 2.
Music AI Sandbox from Goog is kind of fun: Music AI Sandbox, now with new features and broader access.
3D
Gigascale 3D Generation: Demo - by wushuang98.

3DTown: Constructing a 3D Town from a Single Image. No code, but I’m always into these projects.
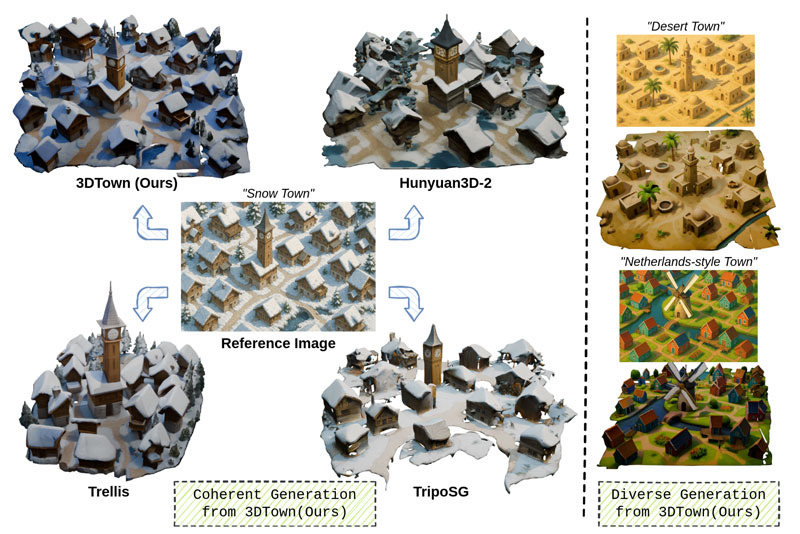
Related, another one of these game sims: Vid2World: Crafting Video Diffusion Models to Interactive World Models.
Veo 3 can do 360 video (you need to do some metadata addition) — link on X, but also my colleague Tom Granger discovered this with ability in Veo 2 as well!
Texture gen is really coming along:
amap-cvlab/MV-Painter - open source 3d texture generator (demo coming).
GT²-GS: Geometry aware texture (including style) transfer for splats. Actually, this is really trippy and worth looking at.

VRSplat: Fast and Robust Gaussian Splatting for Virtual Reality — relevant to my interests (with code).
Misc Web / Fun / Arty
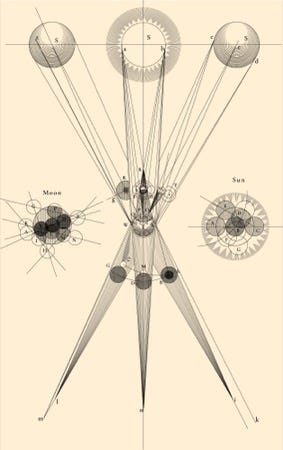
⭐️ Beautiful new work from Nicholas Rougeux, Making of Clavis Cælestis: A Synopsis of the Universe. There is a lovely amount of research involved here, in the history of the document (A Synopsis of the Universe or, The Visible World Epitomiz’d, Written and illustrated by Thomas Wright, 1742) and in finding high quality scans to work from for a custom digital version and lovely poster. Highly recommended for folks interested in historical manuscripts and graphic design work. “This project, like many others, was a labor of love—for astronomy, for antique books, and for spending time carefully crafting something new no one has seen before.”

Three.js shape loaders for GeoJSON and WKT formats: Three.js shape loaders for GeoJSON and WKT formats - gkjohnson/three-geojson. For those map needs.
Redblob games does Mapgen4 Trade Routes. With a cute simulator, too:

A browser-based terrain editor (X gif demo).

Building a Physics-Based Character Controller with the Help of AI | Codrops
games. Tutorial!
Games
Japan’s government just dropped a huge free Minecraft map, and it’s cooler than you think. An elaborate Minecraft map, a recreation of a real-life, massive underground flood control facility located in the Greater Tokyo Area, made by Japan's Ministry of Land, Infrastructure, Transport and Tourism (via Emily Short). An educational project on a massive scale, with NPCs telling you things.
As soon as I arrived in-game, I was greeted by staff at the entrance. NPCs representing staff and visitors were scattered throughout the map, and I could talk to them all. A guide in the second-floor exhibit room taught me about what the facility actually does. Apparently, it’s been activated over 100 times and has prevented an estimated 1.5 trillion yen (about $10.4 billion USD) worth of damage. I also received a handy compass that let me warp to anywhere in the world.
I headed straight to the iconic pressure control tank (the one likened to a temple). Its towering pillars looked just as majestic in Minecraft, recreating the monumental atmosphere quite accurately. According to the guide, the pillars not only support the ceiling but also keep the tank anchored so it doesn’t float due to groundwater.

In less impressive but technically cool Minecraft news, CSS Minecraft - html and css only.
Real-world map data is helping make better games about farms and transportation (Verge). I love real world maps in games.
But once established, the [OpenStreetMap] license gave them access to an entire world of streets, buildings, and even real bus stops. And these do more than just form the game’s world. They’re also used for gameplay elements like simulating passenger behavior. “Schools generate traffic in the mornings on weekdays, while nightlife areas such as bars and clubs tend to attract more passengers in the evenings on weekends,” Polster says.
(Also, this is a cute looking map game coming up, in which you make maps of treasure islands.)
🍓 🥕 This Is One Of The Most Popular Games On The Planet Right Now: “Grow a Garden at one point had over 5 million active Roblox users playing it.” This seems like a pretty chill and easy game, with the giant plus that your plants grow while you’re offline. So you want to go back later and reap the fruit. But I’m always a bit weirded out and worried by these stories of kids making big hits and then someone else taking them over. “The simple farming game was developed by a teenager according to Janzen Madsen, the owner of Splitting Point, a game studio which has taken over management of the game since it hit the big time. Madsen told GameFile that the unnamed creator still retains “like 50 percent of the game.”” Do they retain 50% of the profits? And now this: Roblox’s Hit Farm Game Spurs Underground Digital Fruit Economy: “Roblox Corp.’s 2-month-old Grow a Garden video game has quickly become one of the most-played titles in its history — and spawned a market for virtual crops and livestock that appears to violate company rules.”
Tiny link hits:
Also, get your talk proposals in for Roguelike Conf 2025!
Steam-based Cerebral Puzzle Showcase is on now. With some good discounts and forthcoming excitement (yay Strange Antiquities demo on June 5!)
More games to check, via new games newsletter Bathysphere: Daniel Steger posted his List of Underrepresented Steam Games on Bluesky.
AI
'Fortnite' Players Are Already Making AI Darth Vader Swear. I have not much to say here.
Learning to Play Like Humans: A Framework for LLM Adaptation in Interactive Fiction Games. “This work presents a cognitively inspired framework that guides Large Language Models (LLMs) to learn and play IF games systematically. …(1) structured map building to capture spatial and narrative relationships, (2) action learning to identify context-appropriate commands, and (3) feedback-driven experience analysis to refine decision-making over time.”
“AI, Make me a Video Game” — an article featuring online friends Mike Cook and Matt Guzdial. “Oasis is like “a dream of what Minecraft is, or a memory of what it is,” says Cook. “It isn’t an actual game.”” Deeper than many articles about this, it covers some research topics and AI limits (that I don’t necessarily agree with). The vexed question of what a game is continues to appear in this kind of article, too. With a pointer to Cook’s Puck, a downloadable (here) AI game designer (but not 3d world games).
Related and not awesome: Cliffhanger Studio shutdown by EA, which featured an AI (I believe, in part? now?) NPC relationship system, Nemesis. (Bloomberg piece.)
The highlight of Shadow of Mordor was the Nemesis System, which allowed certain orcs to develop traits and personalities based on the player’s actions throughout the game. For Black Panther, Cliffhanger was building a new system that would expand on those ideas.
Here’s an old article on IGN about Nemesis. And here’s a reddit post about how amazing it was. Slightly related…
Personalized Non-Player Characters: A Framework for Character-Consistent Dialogue Generation. “By combining static knowledge fine-tuning and dynamic knowledge graph technology, the framework generates dialogue content that is more aligned with character settings and is highly personalized. Specifically, the paper introduces a protective static knowledge fine-tuning approach to ensure that the language model does not generate content beyond the character’s cognitive scope during conversations. [bold mine] Additionally, dynamic knowledge graphs are employed to store and update the interaction history between NPCs and players, forming unique “experience-response” patterns.” There’s an abstract meaning rep layer here.
Don’t miss the first one below, too: 👇
Narrative & Creativity Related
⭐️ AI Isn’t Only a Tool—It’s a Whole New Storytelling Medium by Eliot Peper. He wrote backstory for AI character friends the Tolans. (I guess that makes one job for a writer doing AI work?)
Some lessons I’ve learned as a novelist have proven useful writing for this new medium. Some don’t translate at all. More than 800,000 downloads later, I’m here to share three of them so you don’t repeat our mistakes as you experiment with your own AI storytelling projects.
This is super interesting, actually— they started with CYOA branching narrative, but it was too brittle for real user interactions (“Users found edge cases—models would confuse or conflate branches, skip around, or never reach the end. It was a mess.”), so they shifted to “situation” based stories for the Tolans to rely on in different scenarios, inspired by Stephen King. And they brought improv techniques to bear, too:
Now we’re writing prompts that generate new chapters by programmatically reviewing, selecting, and recombining elements from each Tolan’s specific memories, covering any situation we seed, as well as any organic updates spurred by the user.
Artificial Relationships in Fiction: A Dataset for Advancing NLP in Literary Domains. “Built from diverse Project Gutenberg fiction, ARF considers author demographics, publication periods, and themes. We curated an ontology for fictionspecific entities and relations, and using GPT4o, generated artificial relationships to capture narrative complexity.”
Beyond LLMs: A Linguistic Approach to Causal Graph Generation from Narrative Texts. “Experiments on 100 narrative chapters and short stories demonstrate that our approach consistently outperforms GPT-4o and Claude 3.5 in causal graph quality, while maintaining readability. The open-source tool provides an interpretable, efficient solution for capturing nuanced causal chains in narratives.”
Evaluating Text Creativity across Diverse Domains: A Dataset and Large Language Model Evaluator. They build a model to assess creativity (and a dataset).
Diverse, not Short: A Length-Controlled Self-Learning Framework for Improving Response Diversity of Language Models: “Applied to LLaMA-3.1-8B and the Olmo-2 family, Diverse-NS substantially enhances lexical and semantic diversity. We show consistent improvement in diversity with minor reduction or gains in response quality on four creative generation tasks: Divergent Associations, Persona Generation, Alternate Uses, and Creative Writing. Surprisingly, experiments with the Olmo-2 model family (7B, and 13B) show that smaller models like Olmo-2-7B can serve as effective ‘diversity teachers’ for larger models.”
Cooking Up Creativity: A Cognitively-Inspired Approach for Enhancing LLM Creativity through Structured Representations. “We explicitly recombine
structured representations of existing ideas, allowing our algorithm to effectively explore the more abstract landscape of ideas. We demonstrate our approach in the culinary domain with Dish COVER, a model that generates creative recipes.”
NLP / Data Science
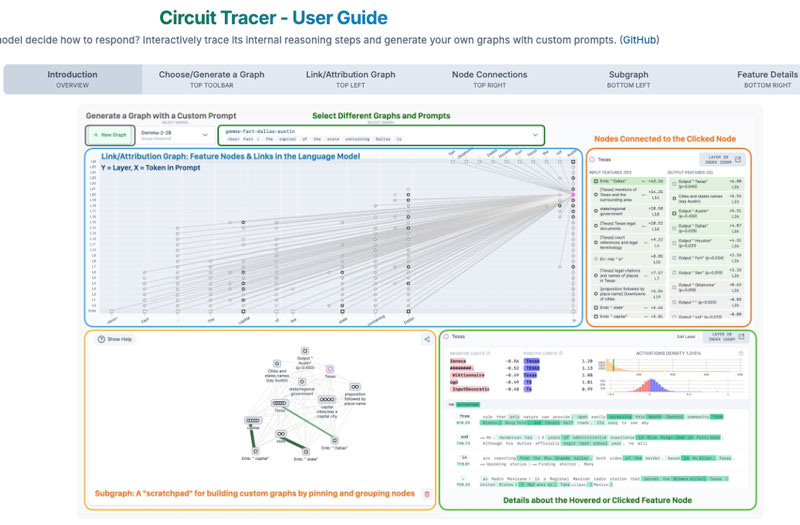
Anthropic has open-sourced circuit-tracing tools so you can play with interpretability. It’s non-trivial play, for sure (check the playground on Neuronpedia):
isaac-fasthtml-workshop — a tutorial on using fasthtml to do a labeling problem.
Applying RL: Fixing Structured Outputs: “So instead of structured output mode, we used reinforcement learning to train an ultra small model (Qwen3-0.6B) to do it instead! All you have to do is feed in the unstructured data with the desired output schema.” Clever. Smol models are good.
NameTag 3. “NameTag 3 is an open-source tool for both flat and nested named entity recognition (NER). NameTag 3 identifies proper names in text and classifies them into a set of predefined categories, such as names of persons, locations, organizations, etc. NameTag 3 achieves state-of-the-art performance on 21 test datasets in 15 languages.” (I don’t think I’ve tested this.)
Coding tools:
Google made an AI coding tool specifically for UI design (Stitch, in Verge). I tried it on a basic site I am working on and actually did like the design it produced.
They (Goog) also released their Jules async coding tool, but I haven’t had time to try it (too busy trying to install cuda on a VM that was supposed to have a working driver — I ended up using Claude Code to help me, since it works at the command line, system level. It was a big help with it’s first Ph.D. level problem for me.)
Also see OpenAI Codex and Mistral’s Agents release.
Stagewise, a plugin for your browser that makes AI coding with web dev a lot easier. You can reference DOM elements and pass them off to Cursor/Windsurf etc.
Both Microsoft and HuggingFace have “MCP for Beginners” courses. Wow. Does Anthropic? they’re responsible 😅.
A searchable UMAP of github (via Leland McInnes). I think this would work better with some smarter higher level embedding notion; I found things that were plugins for the same base app in very different places based on language of the repo. Related—UMAP of ArXiv papers (SoarXiv), but this has a strange game-like UI and needs an overview minimap:

Microsoft’s Chat with a Website: microsoft/NLWeb: Natural Language Web.
Yet another solution for LLM context, in a nice API: python lib Attachments.
In RAG-land, the new movement is to critique standard RAG (especially for code repos) and move to “agentic” RAG, which means (I gather) that an agent LLM is looking stuff up for you using some reasoning. Here’s a useful reference paper from February on it: “These agents leverage agentic design patterns reflection, planning, tool use, and multiagent collaboration to dynamically manage retrieval strategies, iteratively refine contextual understanding, and adapt workflows to meet complex task requirements.” Tbh I’m a little disappointed to be back in magic agency land and away from search problem that are more understandable, but hey. Progress.
Here’s a good writeup on agentic RAG from IBM (no really); here’s one from Weaviate (and code for a multivector reasoning Colbert approach), and this: RAG is dead, long live agentic retrieval — via LlamaIndex. This work from Google covers the problem with insufficient context in RAG apps. There’s a lot going on in RAG-land right now!
One more: Compare and find small RAG models on a HuggingFace arena space, if you still believe in regular RAG.
A Poem: from “Frida’s Earth Mother”
I can say I didn’t kiss a stone frog before I entered their blue house for the third time in seven years. Was there a plea before I said “Do I dare sit in the ghostly chair in a big room of unnatural things, hearing ‘How shall I make you cry?’” ... She could also paint a dark, salty blood of surreal skies & wet soil. Did she brood over dewy blooms with a knowledge of her ancients, saying, I do not wish to see my body forever pierced by some iron spear. She painted mother-wit lying on her back, casting it all in a mirror, but was it her or Diego declaring, “I feel I am murdered by love?”
— By Yousef Komunyakaa, about Frida Kahlo.
Thanks for reading, and cross your fingers for my apartment move,
Just read the piece by Nicholas Rougeux, absolutely bonkers amount of work and such a cool project. I'd never have the patience 😅
And I'm always really looking forward to the newsletter, feels like a breath of fresh air apart from any social media content, like there is still an old web that isn't dead, hidden in the spaces of our attention.
good luck on your move!